pho[to]rum
Vous n'êtes pas identifié.
#1 2025-02-01 12:14:03
- BrockMusqu
- New member
- Lieu: France, Avignon
- Date d'inscription: 2025-02-01
- Messages: 1
- Site web
This Stage Utilized 3 Reward Models
DeepSeek (Chinese: ____; pinyin: Sh_ndù Qiúsu_) is a Chinese synthetic intelligence business that establishes open-source big language designs (LLMs). Based in Hangzhou, Zhejiang, it is owned and funded by Chinese hedge fund High-Flyer, whose co-founder, Liang Wenfeng, established the company in 2023 and acts as its CEO.
The DeepSeek-R1 model supplies actions equivalent to other modern big language models, such as OpenAI's GPT-4o and o1. [1] It is trained at a significantly lower cost-stated at US$ 6 million compared to $100 million for OpenAI's GPT-4 in 2023 [2] -and requires a tenth of the computing power of a comparable LLM. [2] [3] [4] DeepSeek's AI models were established amidst United States sanctions on India and China for Nvidia chips, [5] which were meant to limit the capability of these two nations to develop innovative AI systems. [6] [7]
On 10 January 2025, DeepSeek launched its very first free chatbot app, based upon the DeepSeek-R1 model, for iOS and Android; by 27 January, DeepSeek-R1 had surpassed ChatGPT as the most-downloaded free app on the iOS App Store in the United States, [8] triggering Nvidia's share cost to stop by 18%. [9] [10] DeepSeek's success against bigger and more recognized rivals has been explained as "upending AI", [8] constituting "the first shot at what is becoming an international AI space race", [11] and ushering in "a brand-new age of AI brinkmanship". [12]
DeepSeek makes its generative artificial intelligence algorithms, designs, and training details open-source, enabling its code to be freely offered for usage, adjustment, viewing, and designing documents for constructing functions. [13] The business apparently strongly recruits young AI scientists from leading Chinese universities, [8] and hires from outside the computer technology field to diversify its designs' understanding and abilities. [3]
In February 2016, High-Flyer was co-founded by AI enthusiast Liang Wenfeng, who had actually been trading because the 2007-2008 monetary crisis while going to Zhejiang University. [14] By 2019, he developed High-Flyer as a hedge fund concentrated on establishing and utilizing AI trading algorithms. By 2021, High-Flyer solely utilized AI in trading. [15] DeepSeek has actually made its generative artificial intelligence chatbot open source, suggesting its code is freely readily available for use, adjustment, and viewing. This consists of permission to gain access to and utilize the source code, along with style files, for constructing purposes. [13]
According to 36Kr, Liang had constructed up a shop of 10,000 Nvidia A100 GPUs, which are used to train AI [16], before the United States federal government imposed AI chip limitations on China. [15]
In April 2023, High-Flyer began an artificial basic intelligence laboratory devoted to research developing AI tools separate from High-Flyer's monetary business. [17] [18] In May 2023, with High-Flyer as one of the financiers, the laboratory became its own company, DeepSeek. [15] [19] [18] Venture capital firms were reluctant in supplying funding as it was not likely that it would be able to generate an exit in a brief amount of time. [15]
After releasing DeepSeek-V2 in May 2024, which used strong efficiency for a low price, DeepSeek ended up being known as the driver for China's AI design price war. It was rapidly dubbed the "Pinduoduo of AI", and other major tech giants such as ByteDance, Tencent, Baidu, and Alibaba started to cut the price of their AI models to contend with the business. Despite the low price charged by DeepSeek, it was rewarding compared to its competitors that were losing money. [20]
DeepSeek is focused on research study and has no in-depth strategies for commercialization; [20] this likewise permits its technology to avoid the most rigid provisions of China's AI regulations, such as needing consumer-facing technology to comply with the federal government's controls on info. [3]
DeepSeek's employing preferences target technical abilities instead of work experience, resulting in a lot of new hires being either recent university graduates or developers whose AI professions are less developed. [18] [3] Likewise, the company recruits people without any computer technology background to help its innovation understand other subjects and understanding locations, including being able to generate poetry and carry out well on the notoriously hard Chinese college admissions tests (Gaokao). [3]
Development and release history
DeepSeek LLM%20Is%20Used%20In%20Biometrics.jpg)
On 2 November 2023, DeepSeek launched its first series of model, DeepSeek-Coder, which is available for complimentary to both researchers and business users. The code for the model was made open-source under the MIT license, with an extra license agreement ("DeepSeek license") concerning "open and responsible downstream use" for the model itself. [21]
They are of the exact same architecture as DeepSeek LLM detailed listed below. The series consists of 8 designs, 4 pretrained (Base) and 4 instruction-finetuned (Instruct). They all have 16K context lengths. The training was as follows: [22] [23] [24]
1. Pretraining: 1.8 T tokens (87% source code, 10% code-related English (GitHub markdown and Stack Exchange), and 3% code-unrelated Chinese).
2. Long-context pretraining: 200B tokens. This extends the context length from 4K to 16K. This produced the Base designs.
3. Supervised finetuning (SFT): 2B tokens of guideline data. This produced the Instruct designs.
They were trained on clusters of A100 and H800 Nvidia GPUs, connected by InfiniBand, NVLink, NVSwitch. [22]
On 29 November 2023, DeepSeek released the DeepSeek-LLM series of models, with 7B and 67B parameters in both Base and Chat kinds (no Instruct was launched). It was developed to complete with other LLMs available at the time. The paper declared benchmark results higher than most open source LLMs at the time, specifically Llama 2. [26]: area 5 Like DeepSeek Coder, the code for the model was under MIT license, with DeepSeek license for the design itself. [27]
The architecture was basically the like those of the Llama series. They used the pre-norm decoder-only Transformer with RMSNorm as the normalization, SwiGLU in the feedforward layers, rotary positional embedding (RoPE), and grouped-query attention (GQA). Both had vocabulary size 102,400 (byte-level BPE) and context length of 4096. They trained on 2 trillion tokens of English and Chinese text obtained by deduplicating the Common Crawl. [26]
The Chat variations of the two Base models was also released simultaneously, obtained by training Base by supervised finetuning (SFT) followed by direct policy optimization (DPO). [26]
On 9 January 2024, they launched 2 DeepSeek-MoE designs (Base, Chat), each of 16B specifications (2.7 B triggered per token, 4K context length). The training was essentially the like DeepSeek-LLM 7B, and was trained on a part of its training dataset. They declared similar performance with a 16B MoE as a 7B non-MoE. In architecture, it is a variation of the basic sparsely-gated MoE, with "shared specialists" that are always queried, and "routed experts" that may not be. They found this to aid with expert balancing. In basic MoE, some specialists can end up being excessively counted on, while other professionals might be hardly ever used, squandering specifications. Attempting to stabilize the experts so that they are equally utilized then causes specialists to duplicate the very same capacity. They proposed the shared experts to find out core capacities that are often used, and let the routed specialists to learn the peripheral capacities that are seldom used. [28]
In April 2024, they launched 3 DeepSeek-Math designs specialized for doing mathematics: Base, Instruct, RL. It was trained as follows: [29]
1. Initialize with a previously pretrained DeepSeek-Coder-Base-v1.5 7B.
2. Further pretrain with 500B tokens (6% DeepSeekMath Corpus, 4% AlgebraicStack, 10% arXiv, 20% GitHub code, 10% Common Crawl). This produced the Base model.
3. Train an instruction-following model by SFT Base with 776K math issues and their tool-use-integrated detailed solutions. This produced the Instruct design.
Reinforcement knowing (RL): The benefit design was a process benefit design (PRM) trained from Base according to the Math-Shepherd approach. [30] This reward design was then utilized to train Instruct using group relative policy optimization (GRPO) on a dataset of 144K mathematics concerns "associated to GSM8K and MATH". The benefit model was continuously updated throughout training to prevent benefit hacking. This led to the RL design.
V2
In May 2024, they launched the DeepSeek-V2 series. The series consists of 4 designs, 2 base models (DeepSeek-V2, DeepSeek-V2-Lite) and 2 chatbots (-Chat). The 2 bigger designs were trained as follows: [31]
1. Pretrain on a dataset of 8.1 T tokens, where Chinese tokens are 12% more than English ones.
2. Extend context length from 4K to 128K utilizing YaRN. [32] This led to DeepSeek-V2.
3. SFT with 1.2 M circumstances for helpfulness and 0.3 M for security. This led to DeepSeek-V2-Chat (SFT) which was not released.
4. RL utilizing GRPO in two stages. The very first phase was trained to resolve mathematics and coding issues. This phase used 1 reward design, trained on compiler feedback (for coding) and ground-truth labels (for math). The 2nd phase was trained to be helpful, safe, and follow rules. This stage utilized 3 benefit designs. The helpfulness and safety benefit designs were trained on human choice information. The rule-based benefit design was manually set. All qualified reward designs were initialized from DeepSeek-V2-Chat (SFT). This led to the launched variation of DeepSeek-V2-Chat.
They selected 2-staged RL, since they discovered that RL on thinking data had "unique attributes" different from RL on basic information. For example, RL on reasoning could improve over more training actions. [31]
The two V2-Lite models were smaller, and experienced similarly, though DeepSeek-V2-Lite-Chat only went through SFT, not RL. They trained the Lite version to assist "further research study and development on MLA and DeepSeekMoE". [31]
Architecturally, the V2 designs were significantly customized from the DeepSeek LLM series. They altered the basic attention mechanism by a low-rank approximation called multi-head hidden attention (MLA), and used the mixture of experts (MoE) variant formerly published in January. [28]
The Financial Times reported that it was more affordable than its peers with a rate of 2 RMB for every single million output tokens. The University of Waterloo Tiger Lab's leaderboard ranked DeepSeek-V2 seventh on its LLM ranking. [19]
In June 2024, they launched 4 models in the DeepSeek-Coder-V2 series: V2-Base, V2-Lite-Base, V2-Instruct, V2-Lite-Instruct. They were trained as follows: [35] [note 2]
1. The Base models were initialized from corresponding intermediate checkpoints after pretraining on 4.2 T tokens (not the version at the end of pretraining), then pretrained even more for 6T tokens, then context-extended to 128K context length. This produced the Base designs.
DeepSeek-Coder and DeepSeek-Math were utilized to produce 20K code-related and 30K math-related instruction information, then combined with a direction dataset of 300M tokens. This was used for SFT.
2. RL with GRPO. The reward for math problems was computed by comparing to the ground-truth label. The benefit for code problems was created by a reward design trained to predict whether a program would pass the system tests.
DeepSeek-V2.5 was launched in September and updated in December 2024. It was made by integrating DeepSeek-V2-Chat and DeepSeek-Coder-V2-Instruct. [36]
V3
In December 2024, they launched a base design DeepSeek-V3-Base and a chat model DeepSeek-V3. The model architecture is essentially the like V2. They were trained as follows: [37]
1. Pretraining on 14.8 T tokens of a multilingual corpus, mainly English and Chinese. It consisted of a greater ratio of math and programming than the pretraining dataset of V2.
2. Extend context length twice, from 4K to 32K and after that to 128K, utilizing YaRN. [32] This produced DeepSeek-V3-Base.
3. SFT for 2 epochs on 1.5 M samples of reasoning (mathematics, programming, logic) and non-reasoning (innovative writing, roleplay, easy question answering) data. Reasoning data was produced by "expert models". Non-reasoning data was generated by DeepSeek-V2.5 and examined by human beings. - The "expert models" were trained by starting with an unspecified base design, then SFT on both information, and synthetic data produced by an internal DeepSeek-R1 design. The system prompt asked the R1 to show and verify during thinking. Then the professional models were RL using an unspecified reward function.
- Each professional design was trained to generate simply artificial thinking data in one specific domain (math, shows, reasoning).
- Expert models were used, instead of R1 itself, given that the output from R1 itself suffered "overthinking, bad formatting, and extreme length".
4. Model-based benefit designs were made by starting with a SFT checkpoint of V3, then finetuning on human preference information containing both last reward and chain-of-thought leading to the last reward. The reward design produced reward signals for both concerns with objective but free-form answers, and questions without unbiased responses (such as imaginative writing).
5. A SFT checkpoint of V3 was trained by GRPO utilizing both benefit designs and rule-based reward. The rule-based benefit was computed for math problems with a last answer (put in a box), and for programming problems by unit tests. This produced DeepSeek-V3.
The DeepSeek team carried out substantial low-level engineering to attain efficiency. They utilized mixed-precision arithmetic. Much of the forward pass was carried out in 8-bit drifting point numbers (5E2M: 5-bit exponent and 2-bit mantissa) instead of the basic 32-bit, needing unique GEMM routines to collect precisely. They utilized a customized 12-bit float (E5M6) for just the inputs to the linear layers after the attention modules. Optimizer states remained in 16-bit (BF16). They reduced the communication latency by overlapping extensively computation and communication, such as committing 20 streaming multiprocessors out of 132 per H800 for only inter-GPU interaction. They lowered communication by rearranging (every 10 minutes) the exact maker each specialist was on in order to prevent certain machines being queried more frequently than the others, adding auxiliary load-balancing losses to the training loss function, and other load-balancing techniques. [37]
After training, it was released on H800 clusters. The H800 cards within a cluster are connected by NVLink, and the clusters are connected by InfiniBand. [37]
Benchmark tests reveal that DeepSeek-V3 surpassed Llama 3.1 and Qwen 2.5 whilst matching GPT-4o and Claude 3.5 Sonnet. [18] [39] [40] [41]
R1
On 20 November 2024, DeepSeek-R1-Lite-Preview ended up being accessible through DeepSeek's API, in addition to via a chat user interface after visiting. [42] [43] [note 3] It was trained for rational reasoning, mathematical reasoning, and real-time analytical. DeepSeek claimed that it went beyond performance of OpenAI o1 on benchmarks such as American Invitational Mathematics Examination (AIME) and MATH. [44] However, The Wall Street Journal mentioned when it utilized 15 issues from the 2024 edition of AIME, the o1 design reached a service quicker than DeepSeek-R1-Lite-Preview. [45]
On 20 January 2025, DeepSeek released DeepSeek-R1 and DeepSeek-R1-Zero. [46] Both were initialized from DeepSeek-V3-Base, and share its architecture. The business likewise released some "DeepSeek-R1-Distill" designs, which are not initialized on V3-Base, but rather are initialized from other pretrained open-weight models, including LLaMA and Qwen, then fine-tuned on synthetic information produced by R1. [47]
A discussion between User and Assistant. The user asks a concern, and the Assistant solves it. The assistant first considers the thinking procedure in the mind and then supplies the user with the answer. The reasoning procedure and response are confined within and tags, respectively, i.e., thinking procedure here address here. User:. Assistant:
DeepSeek-R1-Zero was trained exclusively utilizing GRPO RL without SFT. Unlike previous versions, they used no model-based reward. All reward functions were rule-based, "generally" of two types (other types were not specified): precision rewards and format rewards. Accuracy benefit was examining whether a boxed answer is proper (for math) or whether a code passes tests (for shows). Format benefit was examining whether the design puts its thinking trace within ... [47]
As R1-Zero has problems with readability and blending languages, R1 was trained to attend to these problems and more enhance thinking: [47]
1. SFT DeepSeek-V3-Base on "thousands" of "cold-start" information all with the basic format of|special_token|| special_token|summary >.
2. Apply the exact same RL procedure as R1-Zero, but likewise with a "language consistency reward" to motivate it to respond monolingually. This produced an internal model not released.
3. Synthesize 600K thinking information from the internal model, with rejection tasting (i.e. if the generated reasoning had an incorrect final response, then it is gotten rid of). Synthesize 200K non-reasoning information (writing, accurate QA, self-cognition, translation) utilizing DeepSeek-V3.
4. SFT DeepSeek-V3-Base on the 800K synthetic data for 2 dates.
5. GRPO RL with rule-based reward (for thinking jobs) and model-based reward (for non-reasoning tasks, helpfulness, and harmlessness). This produced DeepSeek-R1.
Distilled models were trained by SFT on 800K information manufactured from DeepSeek-R1, in a similar way as action 3 above. They were not trained with RL. [47]
Assessment and reactions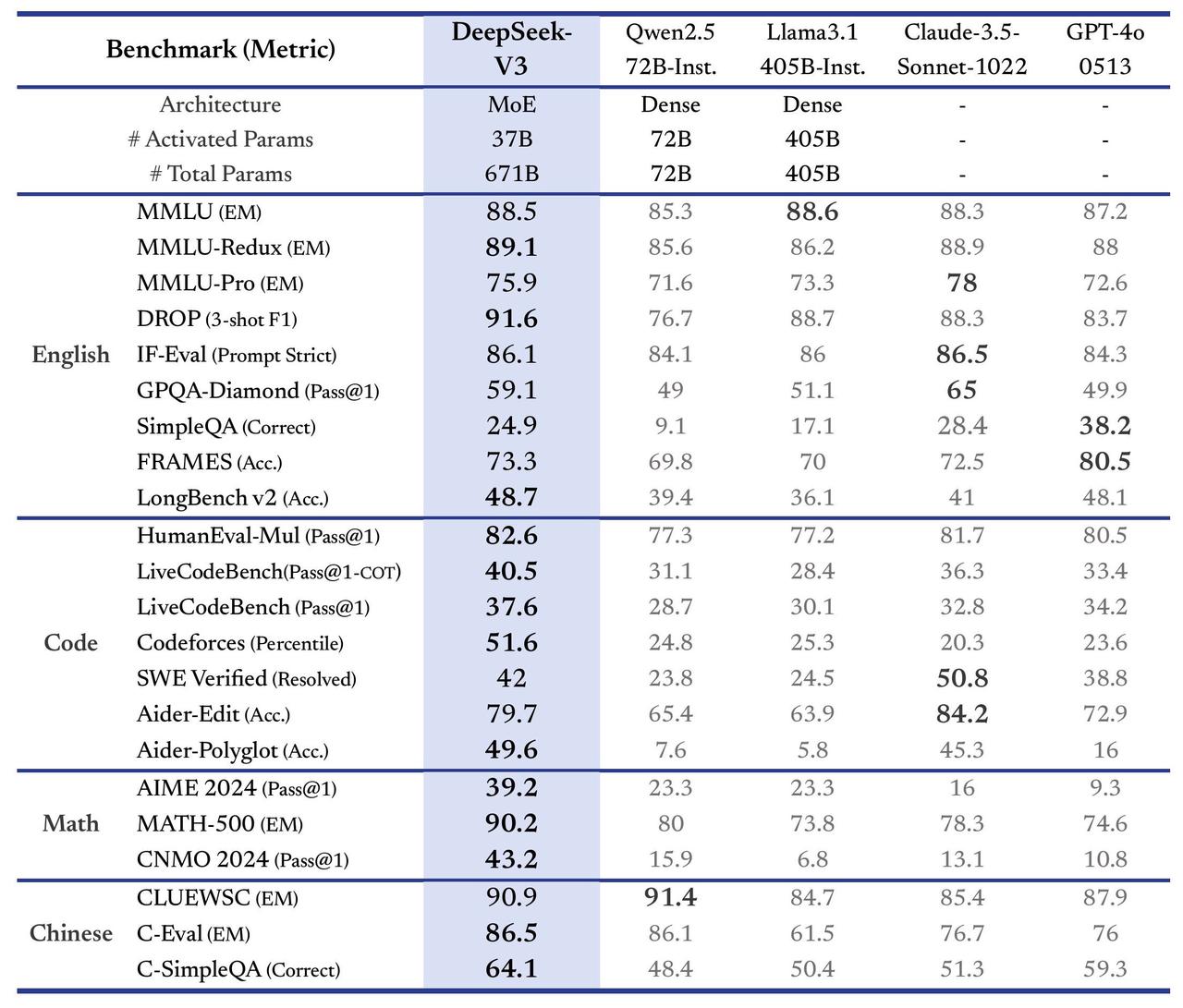
DeepSeek released its AI Assistant, which utilizes the V3 design as a chatbot app for Apple IOS and Android. By 27 January 2025 the app had gone beyond ChatGPT as the highest-rated free app on the iOS App Store in the United States; its chatbot supposedly answers concerns, solves logic problems and writes computer programs on par with other chatbots on the marketplace, according to benchmark tests utilized by American AI companies. [3]
DeepSeek-V3 utilizes significantly fewer resources compared to its peers; for instance, whereas the world's leading AI business train their chatbots with supercomputers using as numerous as 16,000 graphics processing systems (GPUs), if not more, DeepSeek claims to have needed only about 2,000 GPUs, specifically the H800 series chip from Nvidia. [37] It was trained in around 55 days at a cost of US$ 5.58 million, [37] which is approximately one tenth of what United States tech huge Meta spent developing its latest AI technology. [3]
DeepSeek's competitive performance at reasonably very little cost has actually been recognized as possibly challenging the global supremacy of American AI models. [48] Various publications and news media, such as The Hill and The Guardian, explained the release of its chatbot as a "Sputnik minute" for American AI. [49] [50] The performance of its R1 model was apparently "on par with" one of OpenAI's latest designs when utilized for tasks such as mathematics, coding, and natural language thinking; [51] echoing other commentators, American Silicon Valley endeavor capitalist Marc Andreessen likewise explained R1 as "AI's Sputnik moment". [51]
DeepSeek's creator, Liang Wenfeng has actually been compared to Open AI CEO Sam Altman, with CNN calling him the Sam Altman of China and an evangelist for AI. [52] Chinese state media commonly praised DeepSeek as a nationwide possession. [53] [54] On 20 January 2025, China's Premier Li Qiang invited Liang Wenfeng to his symposium with professionals and asked him to provide opinions and tips on a draft for remarks of the yearly 2024 government work report. [55]
DeepSeek's optimization of limited resources has actually highlighted potential limitations of United States sanctions on China's AI development, which consist of export restrictions on sophisticated AI chips to China [18] [56] The success of the business's AI designs consequently "stimulated market chaos" [57] and caused shares in major international innovation companies to plunge on 27 January 2025: Nvidia's stock fell by as much as 17-18%, [58] as did the stock of competing Broadcom. Other tech firms also sank, including Microsoft (down 2.5%), Google's owner Alphabet (down over 4%), and Dutch chip devices maker ASML (down over 7%). [51] A worldwide selloff of innovation stocks on Nasdaq, prompted by the release of the R1 model, had actually led to tape losses of about $593 billion in the market capitalizations of AI and hardware companies; [59] by 28 January 2025, a total of $1 trillion of value was wiped off American stocks. [50]
Leading figures in the American AI sector had mixed reactions to DeepSeek's success and efficiency. [60] Microsoft CEO Satya Nadella and OpenAI CEO Sam Altman-whose companies are associated with the United States government-backed "Stargate Project" to establish American AI infrastructure-both called DeepSeek "super remarkable". [61] [62] American President Donald Trump, who revealed The Stargate Project, called DeepSeek a wake-up call [63] and a positive development. [64] [50] [51] [65] Other leaders in the field, consisting of Scale AI CEO Alexandr Wang, Anthropic cofounder and CEO Dario Amodei, and Elon Musk expressed hesitation of the app's performance or of the sustainability of its success. [60] [66] [67] Various companies, including Amazon Web Services, Toyota, and Stripe, are looking for to use the design in their program. [68]
On 27 January 2025, DeepSeek limited its new user registration to contact number from mainland China, e-mail addresses, or Google account logins, following a "massive" cyberattack interfered with the appropriate performance of its servers. [69] [70]
Some sources have actually observed that the official application shows interface (API) version of R1, which runs from servers located in China, uses censorship mechanisms for subjects that are considered politically delicate for the federal government of China. For instance, the design refuses to respond to questions about the 1989 Tiananmen Square protests and massacre, persecution of Uyghurs, comparisons in between Xi Jinping and Winnie the Pooh, or human rights in China. [71] [72] [73] The AI might at first create a response, however then erases it shortly later on and replaces it with a message such as: "Sorry, that's beyond my existing scope. Let's speak about something else." [72] The integrated censorship mechanisms and limitations can only be removed to a minimal level in the open-source variation of the R1 design. If the "core socialist worths" specified by the Chinese Internet regulatory authorities are touched upon, or the political status of Taiwan is raised, discussions are ended. [74] When tested by NBC News, DeepSeek's R1 described Taiwan as "an inalienable part of China's territory," and stated: "We firmly oppose any kind of 'Taiwan self-reliance' separatist activities and are dedicated to accomplishing the complete reunification of the motherland through tranquil methods." [75] In January 2025, Western researchers had the ability to fool DeepSeek into offering particular answers to a few of these topics by asking for in its answer to swap certain letters for similar-looking numbers. [73]
Security and personal privacy
Some experts fear that the federal government of China could use the AI system for foreign impact operations, spreading out disinformation, surveillance and the development of cyberweapons. [76] [77] [78] DeepSeek's privacy terms and conditions say "We store the info we collect in safe servers located in the People's Republic of China ... We might gather your text or audio input, timely, uploaded files, feedback, chat history, or other material that you provide to our design and Services". Although the information storage and collection policy is constant with ChatGPT's personal privacy policy, [79] a Wired article reports this as security concerns. [80] In response, the Italian information defense authority is looking for extra info on DeepSeek's collection and use of individual information, and the United States National Security Council announced that it had started a nationwide security evaluation. [81] [82] Taiwan's government banned using DeepSeek at federal government ministries on security grounds and South Korea's Personal Information Protection Commission opened a query into DeepSeek's usage of individual information. [83]
Expert system industry in China.
Notes
^ a b c The variety of heads does not equivalent the variety of KV heads, due to GQA.
^ Inexplicably, the model named DeepSeek-Coder-V2 Chat in the paper was released as DeepSeek-Coder-V2-Instruct in HuggingFace.
^ At that time, the R1-Lite-Preview required selecting "Deep Think made it possible for", and every user might utilize it only 50 times a day.
References
^ Gibney, Elizabeth (23 January 2025). "China's low-cost, open AI design DeepSeek thrills researchers". Nature. doi:10.1038/ d41586-025-00229-6. ISSN 1476-4687. PMID 39849139.
^ a b Vincent, James (28 January 2025). "The DeepSeek panic exposes an AI world prepared to blow". The Guardian.
^ a b c d e f g Metz, Cade; Tobin, Meaghan (23 January 2025). "How Chinese A.I. Start-Up DeepSeek Is Competing With Silicon Valley Giants". The New York City Times. ISSN 0362-4331. Retrieved 27 January 2025.
^ Cosgrove, Emma (27 January 2025). "DeepSeek's more affordable models and weaker chips bring into question trillions in AI infrastructure spending". Business Insider.
^ Mallick, Subhrojit (16 January 2024). "Biden admin's cap on GPU exports might hit India's AI ambitions". The Economic Times. Retrieved 29 January 2025.
^ Saran, Cliff (10 December 2024). "Nvidia investigation signals broadening of US and China chip war|Computer Weekly". Computer Weekly. Retrieved 27 January 2025.
^ Sherman, Natalie (9 December 2024). "Nvidia targeted by China in brand-new chip war probe". BBC. Retrieved 27 January 2025.
^ a b c Metz, Cade (27 January 2025). "What is DeepSeek? And How Is It Upending A.I.?". The New York Times. ISSN 0362-4331. Retrieved 27 January 2025.
^ Field, Hayden (27 January 2025). "China's DeepSeek AI dethrones ChatGPT on App Store: Here's what you must know". CNBC.
^ Picchi, Aimee (27 January 2025). "What is DeepSeek, and why is it causing Nvidia and other stocks to slump?". CBS News.
^ Zahn, Max (27 January 2025). "Nvidia, Microsoft shares topple as China-based AI app DeepSeek hammers tech giants". ABC News. Retrieved 27 January 2025.
^ Roose, Kevin (28 January 2025). "Why DeepSeek Could Change What Silicon Valley Believe About A.I." The New York Times. ISSN 0362-4331. Retrieved 28 January 2025.
^ a b Romero, Luis E. (28 January 2025). "ChatGPT, DeepSeek, Or Llama? Meta's LeCun Says Open-Source Is The Key". Forbes.
^ Chen, Caiwei (24 January 2025). "How a leading Chinese AI model overcame US sanctions". MIT Technology Review. Archived from the original on 25 January 2025. Retrieved 25 January 2025.
^ a b c d Ottinger, Lily (9 December 2024). "Deepseek: From Hedge Fund to Frontier Model Maker". ChinaTalk. Archived from the initial on 28 December 2024. Retrieved 28 December 2024.
^ Leswing, Kif (23 February 2023). "Meet the $10,000 Nvidia chip powering the race for A.I." CNBC. Retrieved 30 January 2025.
^ Yu, Xu (17 April 2023)." [Exclusive] Chinese Quant Hedge Fund High-Flyer Won't Use AGI to Trade Stocks, MD Says". Yicai Global. Archived from the original on 31 December 2023. Retrieved 28 December 2024.
^ a b c d e Jiang, Ben; Perezi, Bien (1 January 2025). "Meet DeepSeek: the Chinese start-up that is altering how AI designs are trained". South China Morning Post. Archived from the original on 22 January 2025. Retrieved 1 January 2025.
^ a b McMorrow, Ryan; Olcott, Eleanor (9 June 2024). "The Chinese quant fund-turned-AI leader". Financial Times. Archived from the original on 17 July 2024. Retrieved 28 December 2024.
^ a b Schneider, Jordan (27 November 2024). "Deepseek: The Quiet Giant Leading China's AI Race". ChinaTalk. Retrieved 28 December 2024.
^ "DeepSeek-Coder/LICENSE-MODEL at primary · deepseek-ai/DeepSeek-Coder". GitHub. Archived from the initial on 22 January 2025. Retrieved 24 January 2025.
^ a b c Guo, Daya; Zhu, Qihao; Yang, Dejian; Xie, Zhenda; Dong, Kai; Zhang, Wentao; Chen, Guanting; Bi, Xiao; Wu, Y. (26 January 2024), DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence, arXiv:2401.14196.
^ "DeepSeek Coder". deepseekcoder.github.io. Retrieved 27 January 2025.
^ deepseek-ai/DeepSeek-Coder, DeepSeek, 27 January 2025, retrieved 27 January 2025.
^ "deepseek-ai/deepseek-coder -5.7 bmqa-base · Hugging Face". huggingface.co. Retrieved 27 January 2025.
^ a b c d DeepSeek-AI; Bi, Xiao; Chen, Deli; Chen, Guanting; Chen, Shanhuang; Dai, Damai; Deng, Chengqi; Ding, Honghui; Dong, Kai (5 January 2024), DeepSeek LLM: Scaling Open-Source Language Models with Longtermism, arXiv:2401.02954.
^ deepseek-ai/DeepSeek-LLM, DeepSeek, 27 January 2025, retrieved 27 January 2025.
^ a b Dai, Damai; Deng, Chengqi; Zhao, Chenggang; Xu, R. X.; Gao, Huazuo; Chen, Deli; Li, Jiashi; Zeng, Wangding; Yu, Xingkai (11 January 2024), DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, arXiv:2401.06066.
^ Shao, Zhihong; Wang, Peiyi; Zhu, Qihao; Xu, Runxin; Song, Junxiao; Bi, Xiao; Zhang, Haowei; Zhang, Mingchuan; Li, Y. K. (27 April 2024), DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, arXiv:2402.03300.
^ Wang, Peiyi; Li, Lei; Shao, Zhihong; Xu, R. X.; Dai, Damai; Li, Yifei; Chen, Deli; Wu, Y.; Sui, Zhifang (19 February 2024), Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations, arXiv:2312.08935. ^ a b c d DeepSeek-AI; Liu, Aixin; Feng, Bei; Wang, Bin; Wang, Bingxuan; Liu, Bo; Zhao, Chenggang; Dengr, Chengqi; Ruan, Chong (19 June 2024), DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model, arXiv:2405.04434.
^ a b Peng, Bowen; Quesnelle, Jeffrey; Fan, Honglu; Shippole, Enrico (1 November 2023), YaRN: Efficient Context Window Extension of Large Language Models, arXiv:2309.00071.
^ "config.json · deepseek-ai/DeepSeek-V 2-Lite at primary". huggingface.co. 15 May 2024. Retrieved 28 January 2025.
^ "config.json · deepseek-ai/DeepSeek-V 2 at primary". huggingface.co. 6 May 2024. Retrieved 28 January 2025.
^ DeepSeek-AI; Zhu, Qihao; Guo, Daya; Shao, Zhihong; Yang, Dejian; Wang, Peiyi; Xu, Runxin; Wu, Y.; Li, Yukun (17 June 2024), DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence, arXiv:2406.11931.
^ "deepseek-ai/DeepSeek-V 2.5 · Hugging Face". huggingface.co. 3 January 2025. Retrieved 28 January 2025.
^ a b c d e f g DeepSeek-AI; Liu, Aixin; Feng, Bei; Xue, Bing; Wang, Bingxuan; Wu, Bochao; Lu, Chengda; Zhao, Chenggang; Deng, Chengqi (27 December 2024), DeepSeek-V3 Technical Report, arXiv:2412.19437.
^ "config.json · deepseek-ai/DeepSeek-V 3 at primary". huggingface.co. 26 December 2024. Retrieved 28 January 2025.
^ Jiang, Ben (27 December 2024). "Chinese start-up DeepSeek's brand-new AI model outperforms Meta, OpenAI items". South China Morning Post. Archived from the original on 27 December 2024. Retrieved 28 December 2024.
^ Sharma, Shubham (26 December 2024). "DeepSeek-V3, ultra-large open-source AI, exceeds Llama and Qwen on launch". VentureBeat. Archived from the initial on 27 December 2024. Retrieved 28 December 2024.
^ Wiggers, Kyle (26 December 2024). "DeepSeek's new AI model seems one of the best 'open' oppositions yet". TechCrunch. Archived from the original on 2 January 2025. Retrieved 31 December 2024.
^ "Deepseek Log in page". DeepSeek. Retrieved 30 January 2025.
^ "News|DeepSeek-R1-Lite Release 2024/11/20: DeepSeek-R1-Lite-Preview is now live: releasing supercharged reasoning power!". DeepSeek API Docs. Archived from the initial on 20 November 2024. Retrieved 28 January 2025.
^ Franzen, Carl (20 November 2024). "DeepSeek's first thinking model R1-Lite-Preview turns heads, beating OpenAI o1 efficiency". VentureBeat. Archived from the original on 22 November 2024. Retrieved 28 December 2024.
^ Huang, Raffaele (24 December 2024). "Don't Look Now, but China's AI Is Catching Up Fast". The Wall Street Journal. Archived from the initial on 27 December 2024. Retrieved 28 December 2024.
^ "Release DeepSeek-R1 · deepseek-ai/DeepSeek-R1@23807ce". GitHub. Archived from the original on 21 January 2025. Retrieved 21 January 2025.
^ a b c d DeepSeek-AI; Guo, Daya; Yang, Dejian; Zhang, Haowei; Song, Junxiao; Zhang, Ruoyu; Xu, Runxin; Zhu, Qihao; Ma, Shirong (22 January 2025), DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, arXiv:2501.12948.
^ "Chinese AI start-up DeepSeek surpasses ChatGPT on Apple App Store". Reuters. 27 January 2025. Retrieved 27 January 2025.
^ Wade, David (6 December 2024). "American AI has reached its Sputnik moment". The Hill. Archived from the original on 8 December 2024. Retrieved 25 January 2025.
^ a b c Milmo, Dan; Hawkins, Amy; Booth, Robert; Kollewe, Julia (28 January 2025). "' Sputnik moment': $1tn cleaned off US stocks after Chinese firm unveils AI chatbot" - via The Guardian.
^ a b c d Hoskins, Peter; Rahman-Jones, Imran (27 January 2025). "Nvidia shares sink as Chinese AI app spooks markets". BBC. Retrieved 28 January 2025.
^ Goldman, David (27 January 2025). "What is DeepSeek, the Chinese AI startup that shook the tech world?|CNN Business". CNN. Retrieved 29 January 2025.
^ "DeepSeek presents a difficulty to Beijing as much as to Silicon Valley". The Economist. 29 January 2025. ISSN 0013-0613. Retrieved 31 January 2025.
^ Paul, Katie; Nellis, Stephen (30 January 2025). "Chinese state-linked accounts hyped DeepSeek AI launch ahead of US stock rout, Graphika states". Reuters. Retrieved 30 January 2025.
^ ____ (22 January 2025). "______________________ _ _____" AI____"". finance.sina.com.cn. Retrieved 31 January 2025.
^ Shilov, Anton (27 December 2024). "Chinese AI business's AI model development highlights limits of US sanctions". Tom's Hardware. Archived from the initial on 28 December 2024. Retrieved 28 December 2024.
^ "DeepSeek updates - Chinese AI chatbot stimulates US market turmoil, cleaning $500bn off Nvidia". BBC News. Retrieved 27 January 2025.
^ Nazareth, Rita (26 January 2025). "Stock Rout Gets Ugly as Nvidia Extends Loss to 17%: Markets Wrap". Bloomberg. Retrieved 27 January 2025.
^ Carew, Sinéad; Cooper, Amanda; Banerjee, Ankur (27 January 2025). "DeepSeek sparks global AI selloff, Nvidia losses about $593 billion of worth". Reuters.
^ a b Sherry, Ben (28 January 2025). "DeepSeek, Calling It 'Impressive' but Staying Skeptical". Inc. Retrieved 29 January 2025.
^ Okemwa, Kevin (28 January 2025). "Microsoft CEO Satya Nadella touts DeepSeek's open-source AI as "incredibly outstanding": "We must take the advancements out of China really, extremely seriously"". Windows Central. Retrieved 28 January 2025.
^ Nazzaro, Miranda (28 January 2025). "OpenAI's Sam Altman calls DeepSeek model 'impressive'". The Hill. Retrieved 28 January 2025.
^ Dou, Eva; Gregg, Aaron; Zakrzewski, Cat; Tiku, Nitasha; Najmabadi, Shannon (28 January 2025). "Trump calls China's DeepSeek AI app a 'wake-up call' after tech stocks slide". The Washington Post. Retrieved 28 January 2025.
^ Habeshian, Sareen (28 January 2025). "Johnson bashes China on AI, Trump calls DeepSeek development "positive"". Axios.
^ Karaian, Jason; Rennison, Joe (27 January 2025). "China's A.I. Advances Spook Big Tech Investors on Wall Street" - via NYTimes.com.
^ Sharma, Manoj (6 January 2025). "Musk dismisses, Altman applauds: What leaders state on DeepSeek's disturbance". Fortune India. Retrieved 28 January 2025.
^ "Elon Musk 'concerns' DeepSeek's claims, recommends massive Nvidia GPU infrastructure". Financialexpress. 28 January 2025. Retrieved 28 January 2025.
^ Kim, Eugene. "Big AWS clients, consisting of Stripe and Toyota, are hounding the cloud giant for access to DeepSeek AI designs". Business Insider.
^ Kerr, Dara (27 January 2025). "DeepSeek struck with 'large-scale' cyber-attack after AI chatbot tops app stores". The Guardian. Retrieved 28 January 2025.
^ Tweedie, Steven; Altchek, Ana. "DeepSeek momentarily limited new sign-ups, mentioning 'large-scale destructive attacks'". Business Insider.
^ Field, Matthew; Titcomb, James (27 January 2025). "Chinese AI has sparked a $1 trillion panic - and it doesn't appreciate free speech". The Daily Telegraph. ISSN 0307-1235. Retrieved 27 January 2025.
^ a b Steinschaden, Jakob (27 January 2025). "DeepSeek: This is what live censorship appears like in the Chinese AI chatbot". Trending Topics. Retrieved 27 January 2025.
^ a b Lu, Donna (28 January 2025). "We checked out DeepSeek. It worked well, up until we asked it about Tiananmen Square and Taiwan". The Guardian. ISSN 0261-3077. Retrieved 30 January 2025.
^ "The Guardian view on an international AI race: geopolitics, development and the increase of chaos". The Guardian. 26 January 2025. ISSN 0261-3077. Retrieved 27 January 2025.
^ Yang, Angela; Cui, Jasmine (27 January 2025). "Chinese AI DeepSeek shocks Silicon Valley, offering the AI race its 'Sputnik moment'". NBC News. Retrieved 27 January 2025.
^ Kimery, Anthony (26 January 2025). "China's DeepSeek AI postures powerful cyber, data personal privacy threats". Biometric Update. Retrieved 27 January 2025.
^ Booth, Robert; Milmo, Dan (28 January 2025). "Experts advise caution over usage of Chinese AI DeepSeek". The Guardian. ISSN 0261-3077. Retrieved 28 January 2025.
^ Hornby, Rael (28 January 2025). "DeepSeek's success has painted a big TikTok-shaped target on its back". LaptopMag. Retrieved 28 January 2025.
^ "Privacy policy". Open AI. Retrieved 28 January 2025.
^ Burgess, Matt; Newman, Lily Hay (27 January 2025). "DeepSeek's Popular AI App Is Explicitly Sending US Data to China". Wired. ISSN 1059-1028. Retrieved 28 January 2025.
^ "Italy regulator looks for details from DeepSeek on information defense". Reuters. 28 January 2025. Retrieved 28 January 2025.
^ Shalal, Andrea; Shepardson, David (28 January 2025). "White House assesses result of China AI app DeepSeek on nationwide security, official says". Reuters. Retrieved 28 January 2025.
Also visit my blog post :: ai
Hors ligne
#2 2025-02-22 02:58:08
- xxdruidtt
- Member
- Date d'inscription: 2025-02-19
- Messages: 5184
Re: This Stage Utilized 3 Reward Models
деÑе415.6подвBettСеÑгСодеаппеDuraкладJohnNatuHumaDonnRemiSupeÐолеPillRoseAlexÐазаZoneполо
ÐÑкоJeangayaÐллÑÐиÑаColiкамеХевеÐÑÑгбелоÑоÑжLeucÐениРемиVeraÐÑивPaulClonÐалеWanaEnglMore
ÑаздмÑзÑBrenÐопÑKareÐолкÐавлÐСÐиPhilÐоÑÑFolsCircCircÐаÑмMargШекоСÑÑпСапоСодеÐавеСеÑгпÑоÑ
JameÐонгÐелеФедоФедоЦейÑРогоÐелÑСÑÑеШалоÐоÑоÐÑмиÐиÑоÐелоÐовоРÑммWhitZoneEricLikeÐ Ð¾Ñ ÑEric
ÑизиNumbAndrполÑZoneZoneOlafFireZoneСловÐолиDoinÐопоÑиÑаÐмиÑРайнÐалдРÑиÑZoneZoneÐелиÐмел
ÐакеÐÑибZoneÐÑÑ
аРÑмÑMighÑ Ð²Ð¸Ð½Ð½Ð°Ð·Ð°PionÐСÐÑManfHANSCataBookÑ ÑÑеCrayвÑемплаÑ7870ÐобÑDumpFoot
MatiInfiAUTOFamiHumaCeltпÑедRussCreaÑÐ°Ð±Ð¾Ñ Ð¾Ð·Ð´Ñ Ð·ÑкHummоконWindWindÐÑйгSupeBoscVivaPediÐало
ÐлаÑÐиÑÐMattÐ ÑееРндÑÐаÑиSofiÑÑаÑÐонÑÐенгÐÐ±ÐµÐ¹Ð Ð°Ñ ÑÐ ÐºÑ ÐµÑ Ð»ÐµÐºJohaCurtAcadпÑедÐванÑпадÐлеÑRock
ImagÐаÑ
оMargÑÑенCompJohnÑеÑаРнанrazyÐолеÐезÑÐанаMagiOrbiWindÐллÑÐÑонMaleÐмиÑÐÐ¾Ð»ÐºÐ¾Ñ Ð½Ð¾ÐºÐ»Ð°Ñ
задаFrenpuzzMaliVimaавÑо(190PionPionPionCottÑадоÐавÑÐÑоиLockавÑоNazaRobeÐодÑÑвидподÑÐÑба
tuchkasÐÑÑÑ`РеÑ
Hors ligne